

I had been wanting to learn some basic datamining for a while, in particular with social media, specially Twitter. With the last Barcelona vs Madrid game, I had the opportunity to play around a bit. This is my datamining of #ElClasico.
Tools
For this article, I decided to use Python. As far as I know, the two main languages for datamining are R and Python: I chose the latter because of its proximity to Ruby, my main language.
As DB, I picked MongoDB. I needed something that I could modify easily, so my choice needed to be schemaless. And I did some very minor things with Mongo some time ago.
You can find the methods I developed for this article in my Pipper repo.
The sample
Taking tweets from the Twitter API is not so simple. Without a paying access, I decided that the best way for me to take tweets was using search. The tweets you can get through search are limited and you can only fetch tweets from until 10 days before the search, but I thought this would be enough to get a good sample.
For getting it, I used the twitter python package for creating an API access. With it, getting tweets was as simple as using the getSearch method. After some documentation reading, my query evolved to this:
api.GetSearch(query + " -filter:retweets", count=100, result_type="recent", include_entities=True, max_id=final_tweet)
- The first, unnamed parameter is obvious: the search query. The query will be anything that we want, in the case of this exercise, we used
"#ElClasico". We add the-filter:retweetsflag to avoid getting repeated tweets through retweets. - The
countoption limits the quantity of tweets we will get from the query. Unfortunately 100 is the maximum. It defaults to 15, so we set to max. - The
result_typeparameter sets which tweets will be returned in the search, the most popular ones or the most recent. There is also a mixed option, which is the default. - The
include_entitiesoption defines if we will get related entities of the tweet, like hashtags and mentions to users. - The
max_idparameter lets us to set the maximum id of the tweets we will get. Given that the id tweets has a direct relationship to its time creation, we can use this to filter our results by date. - You can find the full documentation here.
For getting the sample, we picked two random tweets; one some hours before the game (start tweet), and another some hours after (end tweet). The start tweet of the sample was written at 17:08:35 and the final at 00:01:24. We set a loop, that starts with the final_tweet parameter as the id of the end tweet, resets it to the earliest picked one, and only finishes when we have a tweet written before the start tweet. With this, we got a full sample of exactly 92.918 tweets.
This number is not so big as it might sound. I have read that during the game around 5.000 tweets were written: that means 450.000 only during the game. Of the 92.918 tweets, 42.865 were published in between the start and the end of the game. That means that the sample is less than 10% of the full quantity of tweets. However, I think that it's still a pretty good aproximation.
In our DB we saved the tweets with the following fields:
lang: The language of the tweet.favorited: If the tweet has been marked as favorite by the authenticated user.text: The text of the tweet.truncated: If the value oftexthas been truncated.created_at: The time of the creation inStringformat.hashtags: An array of entities with information about the hashtags of the tweet.retweeted: If the tweet has been retweeted by the authenticated user.source: A link to the source type of the tweet.user: An entity with information on the author.id: The id of the tweet.
However, you can get more information on any tweet from the Twitter API. You can read a full overview of this in the Twitter documentation.
Stratifying
Of course, this data needs to be stratified, at least in some basic way. The most obvious way is to define which tweets were written during the game, and in which of its two parts.
For stratifying our little DB, we will add the following attributes to all the tweets:
datetime: Thecreated_atattribute of the tweet withDatetimetype.minute: Dividing the full sample in minutes and starting at 0, in which minute was the tweet published. It gets to 413.during_game: If the tweet was published in between the start and the end of the match.game_half: The half of the game in which the tweet was published if any.minute_half: The minute in the half of the game in which the tweet was published if any.
For defining the start and the end of each half, we used some selected tweets. In this, the official account of Real Madrid, @realmadrid, was very useful: they followed the game in a slightly more precise way that their Barcelona counterpart.
Start of the game tweet. (20:02:35)
¡Comienza el Barcelona-Real Madrid! ¡Vamos a por el liderato! #ElClásico #RMLive— Real Madrid C. F. (@realmadrid) marzo 22, 2015
Half-time tweet (20:47:56).
DESCANSO: Barcelona 1-1 Real Madrid (Mathieu, 19’ / Cristiano Ronaldo, 31’) #ElClásico #RMLive pic.twitter.com/XNolfSby2p— Real Madrid C. F. (@realmadrid) marzo 22, 2015
Second-half tweet. 21:03:27
¡Comienza la segunda parte en el Camp Nou! Barcelona 1-1 Real Madrid #ElClásico #RMLive— Real Madrid C. F. (@realmadrid) marzo 22, 2015
End of the game tweet. 21:51:44
FINAL: Barcelona 2-1 Real Madrid (Mathieu, 19’; Luis Suárez, 55’ / Cristiano Ronaldo, 31’) #ElClásico #RMLive pic.twitter.com/Ypb6t7FB6N— Real Madrid C. F. (@realmadrid) marzo 22, 2015
With this, we can start to get some statistics.
Languages
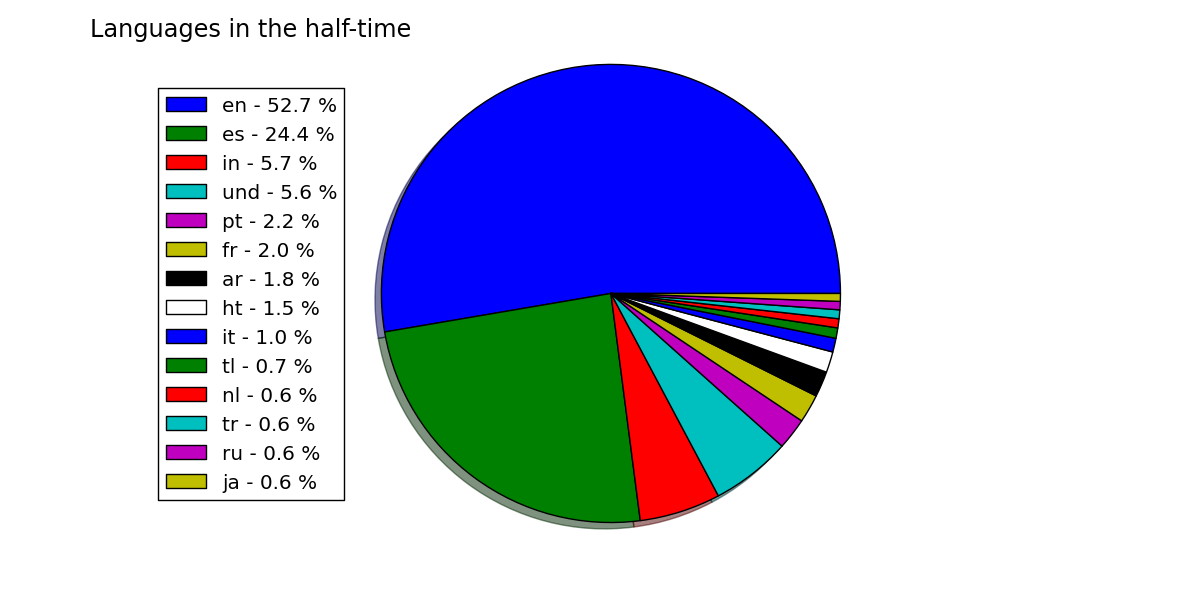
One of the most basic things that you can say about a tweet -and any piece of text, really- is in which language is written. This shows which languages were used for tweeting with #ElClasico:
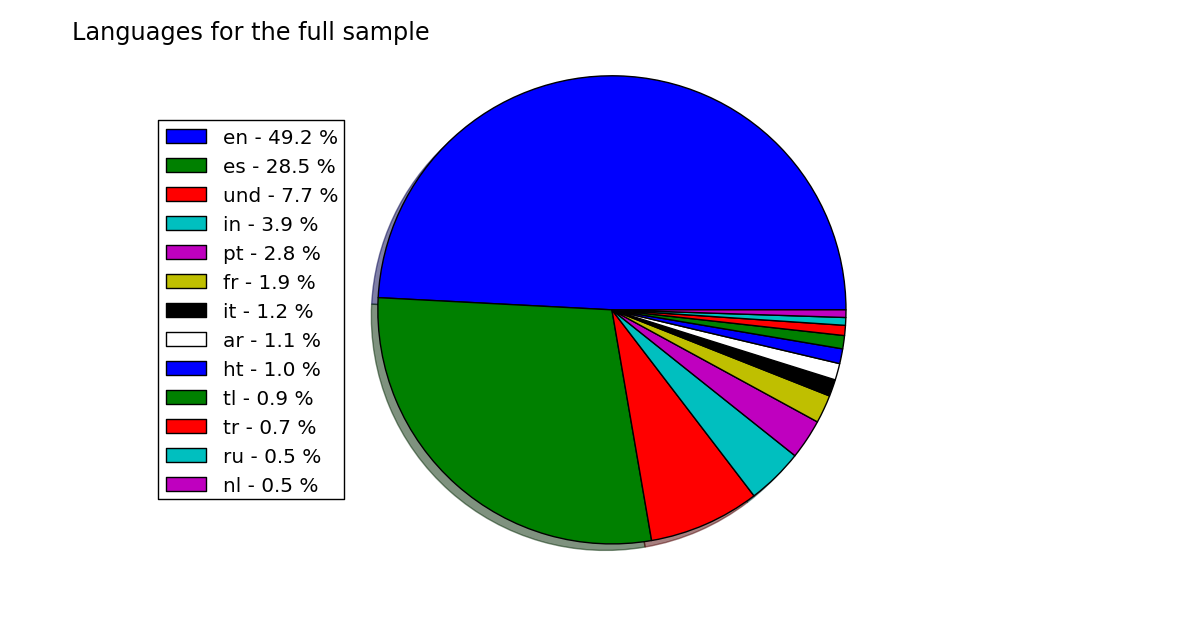
Some of the main conclusions:
- As expected, the two main languages were English and Spanish. As a Spaniard, it surprised me seeing English as the most used language with such a distance.
- Indonesian gets an unexpected third place. This fact is clear as some Indonesian accounts are into the most mentioned ones (#fcbarcelona_id). Another language that does unexpectedly well is Tagalog, the main language of the Philippines (8th).
- From then on, the next languages are the ones that you would expect: Portuguese (4th), French (5th) and Italian (6th).
- Surprisingly, German is not even the 10 most used languages.
- No, so far I haven't counted wrong.
undstands for undefined.htis a code that I haven't been able to decipher, but its tweets don't have a common language, and usually are in English or Spanish.
But this data has not been stratified at all. It still has a lot of things to say. The most obvious division that I could think of, was to divide the tweets by time. Specifically, I wanted to take the tweets that were written between the start and the end of the game.
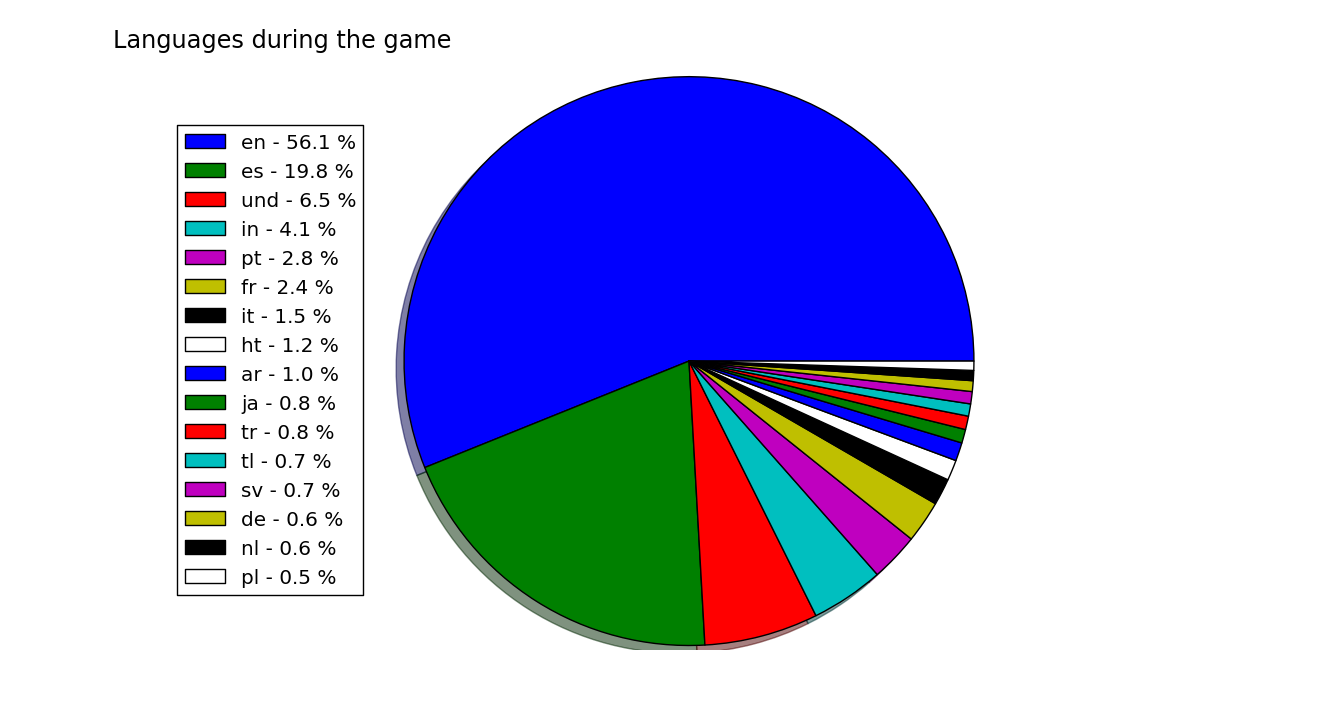
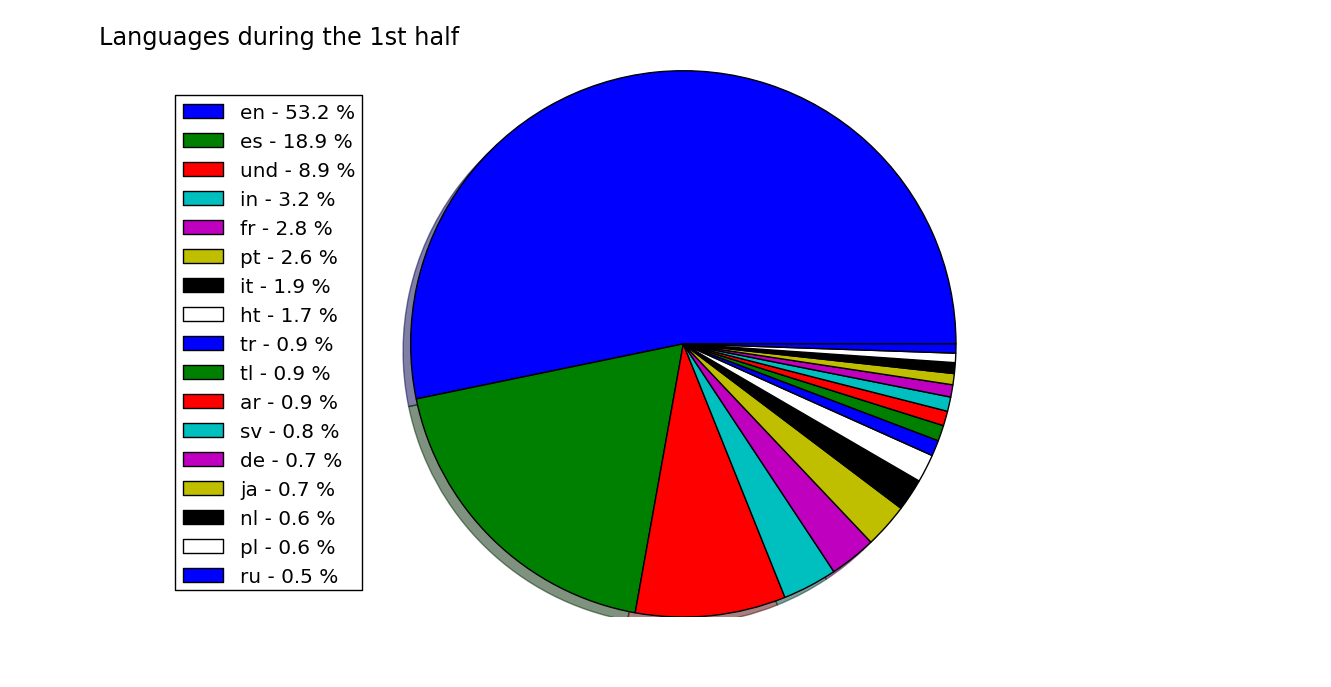
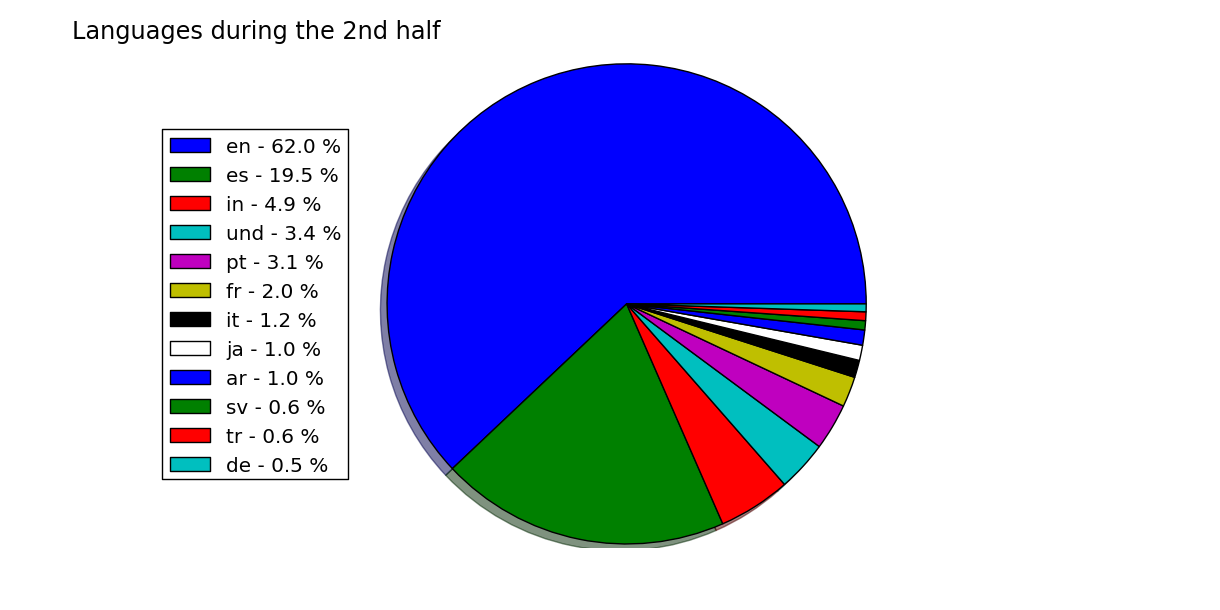
This points to something interesting: apparently the Spanish-speaking community does not tweet as much during the game. Two possible explanations come to my mind. One, that this community is not so used to live-tweeting as their English-speaking counterparts. The other, which I prefer slightly, is that they are just too engaged in the match, so they just want to focus on the game.
Locations
Another interesting issue about the #ElClasico tweets is its location. Twitter offers us a way to locate the tweet, but only a minority of the tweets have it available: around 8% in a tested subsample. However, we can get from the location of a user. This doesn't cover the 100% of the cases, but an important quantity: 63.005 of the 92.918 (67.81%). It may be of interest to say that there are some users in the sample that appear more than once: 62.748 users wrote our 92.918 tweets.
However, finally I decided not to do an analysis of this. The main reason is lack of time: it's already been more than one month since the match, and I wanted to publish this as soon as possible. The location analysis presented a particular difficulty: the field is only a string set by the user, and it can contain anything. Los Angeles can be showed as "L.A.", "LA, CA, US" or "Los Angeles, United States of America". However, ordering this it's not impossible and probably not even hard: I just preferred to publish earlier.
Mentions
Of the 92.918, only 26.774 contain at least one mention (28.81%). In the mentioning tweets, we count 41.731 mentions (1.56 mentions per tweet). This is the tweet with most mentions:
@messi10stats @Samir_FUT @FlFAKlNG @TomInceYT @Wagers_ps4_FUT @futmo66 @BzBookies_ @FUT15_PIRANHA @GuarinFUT @ImAxron who👆 #ElClasico— Evauliò (@Evaulio) marzo 22, 2015
After giving some glory to @Evaulio, let's get some more data. This is the list of the most mentioned accounts:
- @LaLiga - 6497
- @FCBarcelona - 6099
- @realmadrid - 6032
- @FCBarcelona_es - 5058
- @3gerardpique - 1746
- @LuisSuarez9 - 1442
- @Cristiano - 1155
- @realmadriden - 969
- @neymarjr - 408
- @Benzema - 251
- @GarethBale11 - 199
- @elclasico - 174
- @kobebryant - 148
- @FCBarcelona_cat - 114
- @TheSportMatrix - 109
- @RayHudson - 99
- @beINSPORTSUSA - 98
- @SergioRamos - 97
- @fcbarcelona_id - 91
- @MarceloM12 - 81
- @Squawka - 78
- @TeamMessi - 72
- @jamesdrodriguez - 71
Some observations:
- Barcelona wins the mention fight!
- Yep, Messi does not have a Twitter account. This fact shows an obvious weakness for any kind of analysis based on Twitter mentions: whatever does not have an account, does not exist.
- The curious case of @elclasico. Apparently, many users don't understand the difference between a hashtag (#) and a mention (@), and they mentioned an empty, private account with 20 followers. He got 12th, just after Gareth Bale. What a genius.
Only with players:
- @3gerardpique - 1746
- @LuisSuarez9 - 1442
- @Cristiano - 1155
- @neymarjr - 408
- @Benzema - 251
- @GarethBale11 - 199
- @SergioRamos - 97
- @MarceloM12 - 81
- @jamesdrodriguez - 71
- @officialpepe - 58
- @CasillasWorld - 53
- @andresiniesta8 - 45
- @IllarraOfficial - 44
- @isco_alarcon - 41
- @MrAncelotti - 38
- @Mascherano - 33
- @IvanRakiticFCB - 31
- @DaniAlvesD2 - 29
- @C1audioBravo - 24
- @_Pedro17_ - 24
- @LUISENRIQUE21 - 23
- @ToniKroos - 22
- @jordialba - 18
- @DaniCarvajal92 - 16
Some players got many mentions without even playing. For example, James, that was injured and didn't even travel to Barcelona: I do suspect that this is related with Colombian users tweeting a lot, as shown in my preliminary (and unpublished) analysis of the tweeters location. Also Illaramendi and Pedro didn't get to play.
However, it may be more interesting to check the most mentioned accounts only during the game (two halfs).
Most mentioned players during the game:
- @Cristiano - 703
- @LuisSuarez9 - 304
- @Benzema - 141
- @neymarjr - 123
- @GarethBale11 - 103
During the first half:
- @Cristiano - 635
- @Benzema - 105
- @GarethBale11 - 92
- @neymarjr - 42
- @LuisSuarez9 - 35
During the second:
- @LuisSuarez9 - 269
- @neymarjr - 81
- @Cristiano - 68
- @Benzema - 36
- @isco_alarcon - 22
A curious issue: Piqué got, comparatively, much less mentions during the game. And the fact is that he did a pretty good match.
In this analysis of mentions we found out something basic: an analysis of any event is fundamentally flawed if the protagonists don't have an official Twitter account. In this case, this is very obvious for Messi, and probably for other players that had an important role during the match. We will go further on this issue in the next section.
Goals and its effects in Twitter
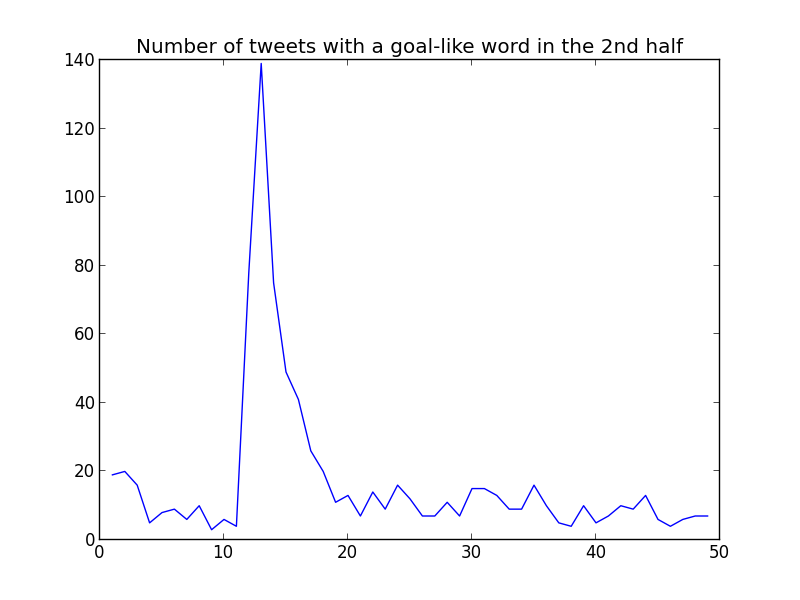
What happens in Twitter when a team scores a goal? Well, first of all, people tweets more. Let's see a tweets by minute graph:
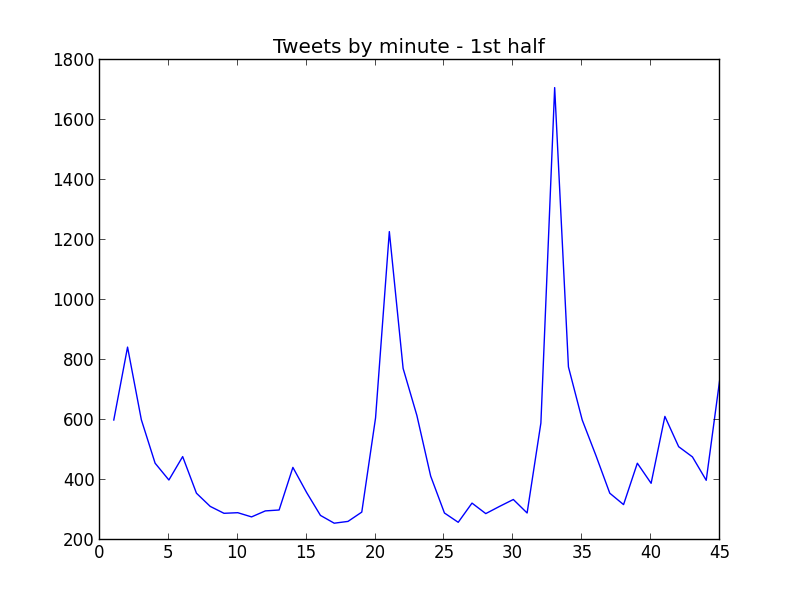
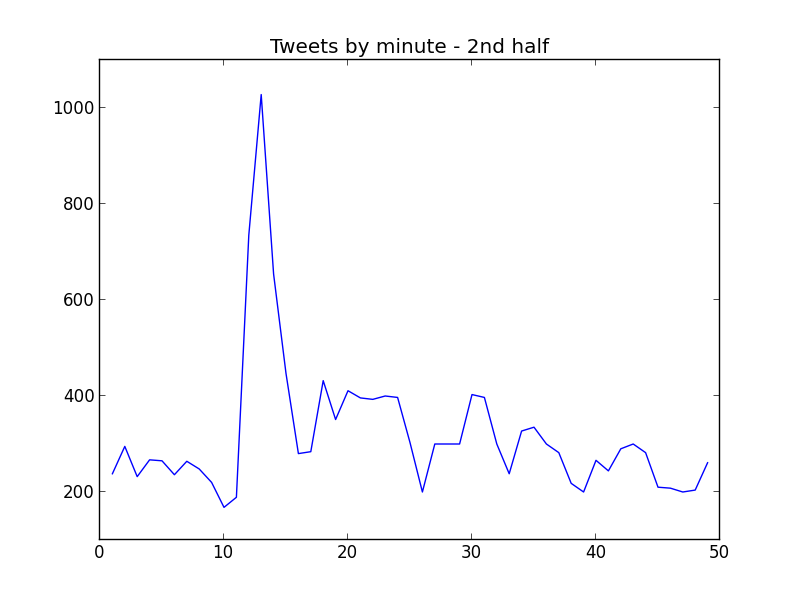
Yes, the peaks match closely the goals (1st part: 19' and 31'; 2nd part: 10').
But hypothetically it could be that tweets increased for some other reason. What are the tweeters saying? Are they shouting "GOAL"? For detecting tweets containing "goal-like" words, we will use the following regular expression: ".*?(\s+|\A)goa?l?(\s+|\z).*". This basically means that we search for "goal" and "gol" (Spanish). For making it case-unsensitive I used the following command: re.compile(".*?(\s+|\A)goa?l?(\s+|\z).*", re.IGNORECASE).
These are the results:
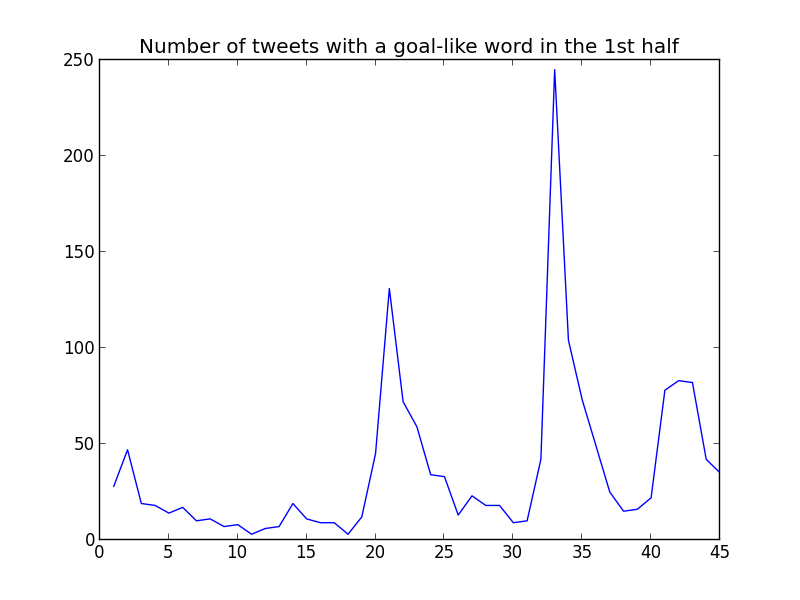
And the percentage of tweets with a "goal-like" word per minute in each half:
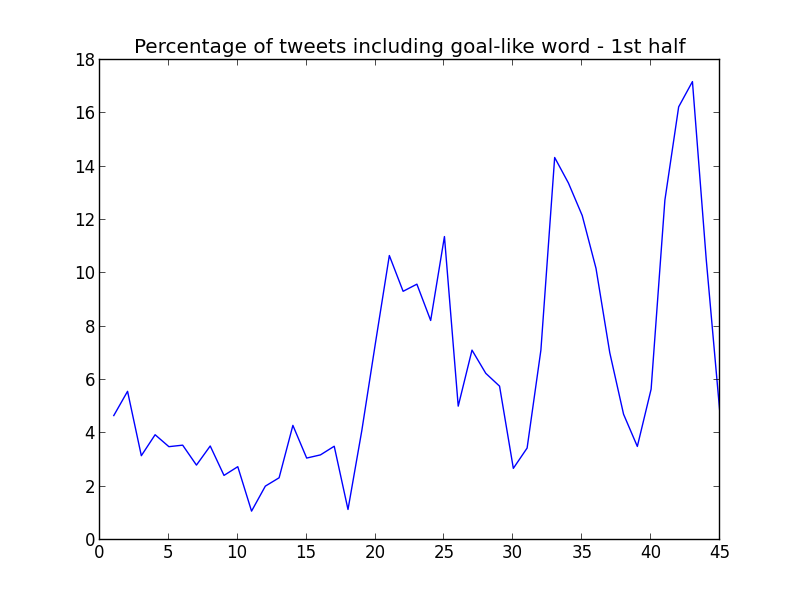
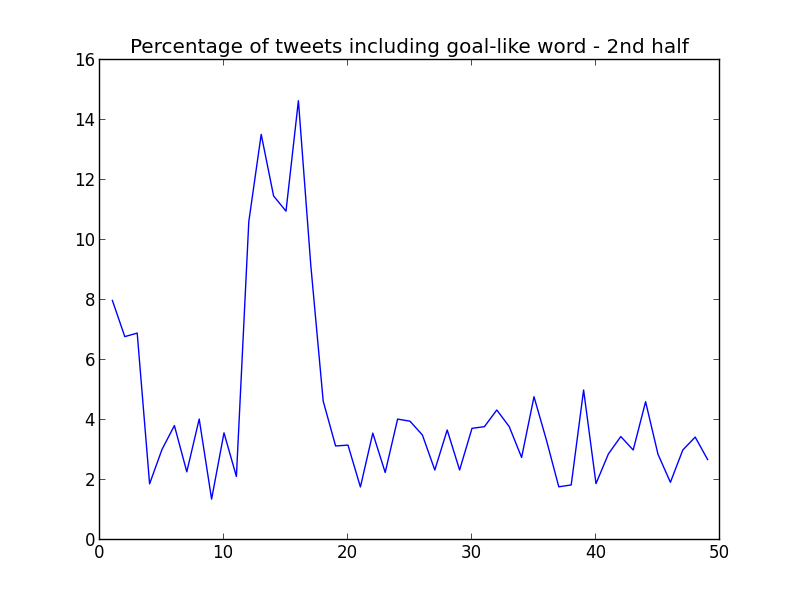
In the first graph I found an unexplainable mystery: the peak in goal percentage at the end of the 1st half. However, I read the tweets and this is what I found:
GOAALLLLNO: Bale with the goal but was given as offside! Still 1-1 #ElClásico— 850 Sports Digest (@850sportsdigest) marzo 22, 2015
Yes, Gareth Bale had a goal disallowed by a close offside in the last minutes of the 1st half. I had forgotten completely about this fact. The disallowed goal was enough to increase the quantity of "goal-like" words, but not enough to excite the users for creating a peak in total number of tweets.
Let's continue. Could we even guess the name of the scorers? Well, let's check the mentions per minute of the 5 most mentioned players of each half:
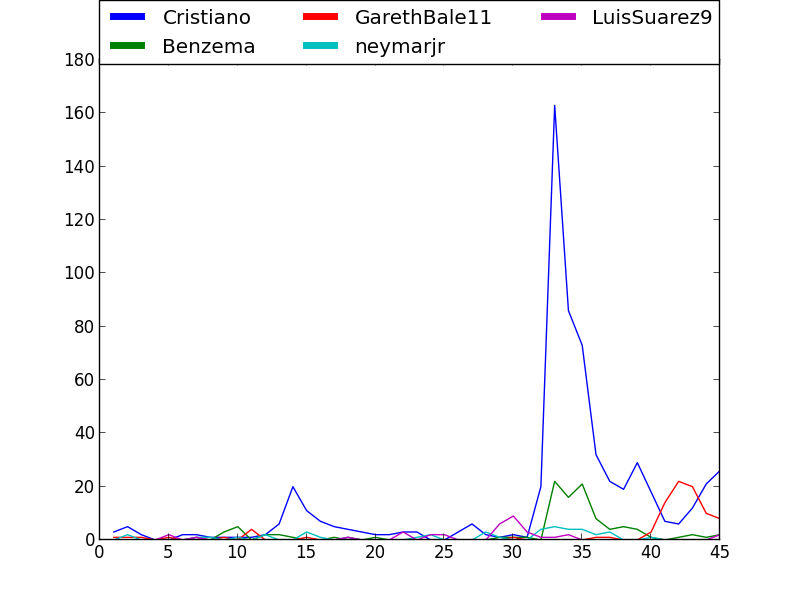
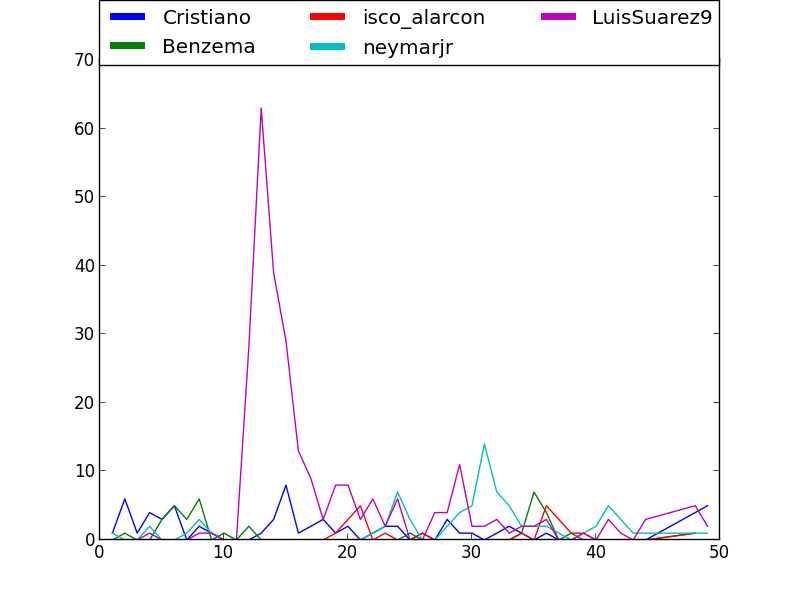
Yes, you can guess who scored at 31' of the first half and at 10' of the second. Actually, the results are kind of spectacular. More than half (50.7%) of the mentions to @Cristiano were tweeted in the three minutes after his goal. 59.1% of the mentions to @LuisSuarez9 were published in the 4 minutes after the goal.
But what happens with the first goal? Well, the weakness of the mention analysis appears here again. The scorer player, Jérémy Mathieu, does not have an official account. This is what happens if we check for tweets including his name ("Mathieu") during the first half:
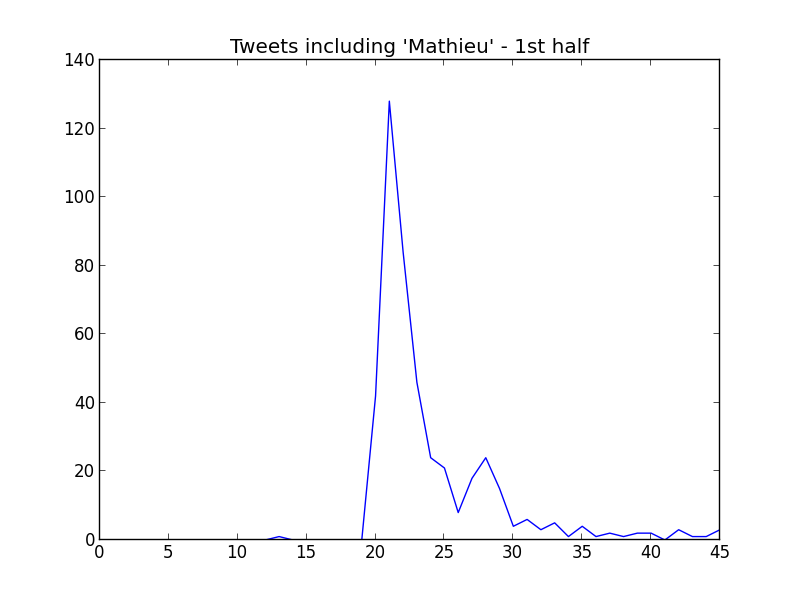
Since the beginning of this little game, I wanted to prove something: that is pretty easy to get the result of a game through datamining. I believe that the data I just presented proves it upto a certain point.
Conclusion
I think I have learnt a few things about datamining Twitter. First of all, mentions are much less important than I thought. This is because -as I wrote before- not every concept and every person is represented by a Twitter account, which makes the analysis unbalanced. By contrast, I realized that text analysis of the tweets . I must admit that the little hipster in me wanted to avoid something so classic as an analysis of the text, but in this case, classic rocks.
If there is a second edition of this, I would center more on the text analysis. I would also work on a way to stratify the tweets by location, that, as I said, would take some time at the beginning but it's not extremely complex. I would have liked to do more stats checking percentages of tweets doing something, as the goal graph was very surprising for me.
An interesting idea would be to use some natural language processing on the tweets. Recently, in a Hackathon, I was able to use AlchemyAPI, in particular its sentiment analysis feature.
In any case, I developed some tools and got some experience that will be useful next time.
As you can see, it's a field with plenty of possibilities. This was just a little introduction. If you arrived until here, thanks! And please, comment. :)